05. NumPy Arrays
NumPy Arrays
Now that we've loaded the data in Pandas, we need to split the input and output into numpy arrays, in order to apply the classifiers in scikit learn. This is done in the following way: Say we have a pandas dataframe called df, like the following, with four columns labeled A, B, C, D:
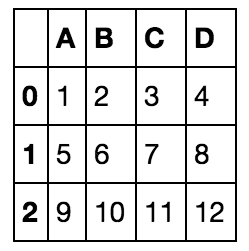
If we want to extract column A, we do the following:
>> df['A']
0 1
1 5
2 9
Name: A, dtype: int64Now, if we want to extract more columns, we just need to specify them, as follows:
>> df[['B', 'D']]And the result is the following DataFrame:
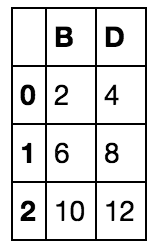
And finally, we turn these pandas DataFrames into NumPy arrays. The command for turning a DataFrame df into a NumPy array is very simple:
>> numpy.array(df)Now, try it yourself! Working with the same dataframe that we loaded in pandas previously, split it into the features X, and the labels y, and turn them into NumPy arrays.
Note: The capitalization may look strange, as X is capitalized whereas y is lowercase, but this is standard notation, as X represents a matrix of (maybe) several columns, and y a single column vector.
Start Quiz: